We've got up and running with Raven DB for our new project, which has been a delight to use from a code perspective, but one of the big gaps for me is figuring out how to do SQL like queries. I'm not too bad at putting a SQL query together as something I do semi-regularly as part of my job, so I thought it shouldn't be too much of a stretch to start pulling some statistics.
I was wrong.
If you're using the .NET client, this is not something you particularly need to worry about as Raven will dynamically create indexes for you based on your LINQ query, which is awesome. My particular scenario is using the Raven web admin pages to do a query that I'm not particularly interested in coding - I just want to see some numbers quickly.
I'll talk you through the steps that I've gone through to get a simple query working, hopefully its of some benefit to you. To start with you should know that RavenDB search is powered by Lucene - we'll be looking at that in a bit. I'm going to start with a data set of animals :
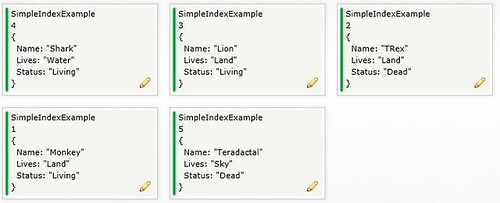
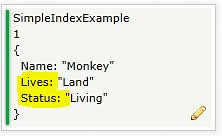
What I'd like to see in the browser is a list of all the living land animals. What this means is we want to do a SQL equivalent of where on 2 of the fields: Lives AND Status.
To make these two columns queryable we need to make an index - unlike SQL we can't just query whatever we want whenever we want - we've got to tell Raven which fields we're going to do a query on. To do this jump over to the 'Indexes' section and 'Create an Index'. What we're going to do is create a document that maps to the columns we need to query, so give your index a name and jump into the 'Maps'.

A breakdown of the parts:
from animals: animals is just the alias for the document we're going to refer to in the selectin docs.SimpleIndexExample: this provides the source for the map - docs is generally all documents in the database, and SimpleIndexExample is the document typeanimals.Lives and animals.Status are the two columns we want to query on
Getting back to the point, I'm going to put together a query to get a list of all living land animals. Now that the index is created, we can click on it and use it to do a query (it'll look different depending on which version of Raven you've got running, but hopefully you'll be able to find the 'Query' section)
Creating the query is just a matter of telling Raven which field you want to query on, and value to restrict it to, so it should look something like this (by the way, you can get some auto-completion on the map field by pressing ctrl + space):
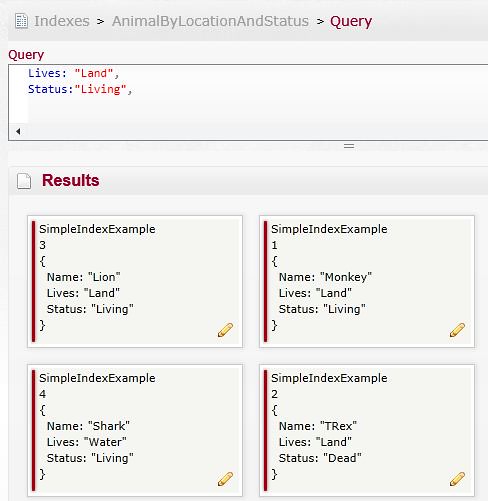
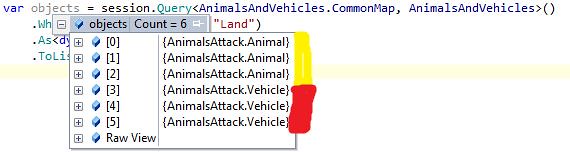
If you haven't picked it up, there's a problem with our result set - we're getting a Shark and TRex - this is not good! The problem is Lucene is looking for anything that matches the query, effectively doing an 'OR' on our statement. What we need to do is tell Lucene to require that a certain value is present - this is just putting a '+' symbol at the start of each required field:

For heaps more info about using Lucene to query have a look at the Lucene Query Parser Syntax Page
Please let me know if you have any comments, ways I can think about this better as this is still a very new area for me, or if you've found it helpful.